5.1 Lecture slides
5.2 Using an API to Collect Text Data
An Application Programming Interface (API) is often the most convenient way to collect well-structured data from the web. We will cover an example here of getting data using the Guardian Newspaper API using the guardianapi package and analysing it using quanteda.
5.3 Packages
You will need to load the following packages before beginning the assignment
5.3.1 Authentication
In theory,1 the Guardian API only requires very minimal effort to access. In particular, to access the API you need to register for a developer API key, which you can do by visiting this webpage. You will need to select the “Register developer key” option on that page:
1 In my experience, the interfaces for both the APIs themselves, and the R packages desgined to access those APIs, are not terribly stable. This is an indirect way of saying: if this code doesn’t work for you, and you cannot access the API in class today, don’t blame me! Instead, think of it as a lesson of all the potential dangers you might face by using tools like this in your research process. Kevin Munger has a nice cautionary tale about this here.

Once you have clicked that button, you will be taken to a page where you can add details of your project.
Fill in the details on that form as follows:
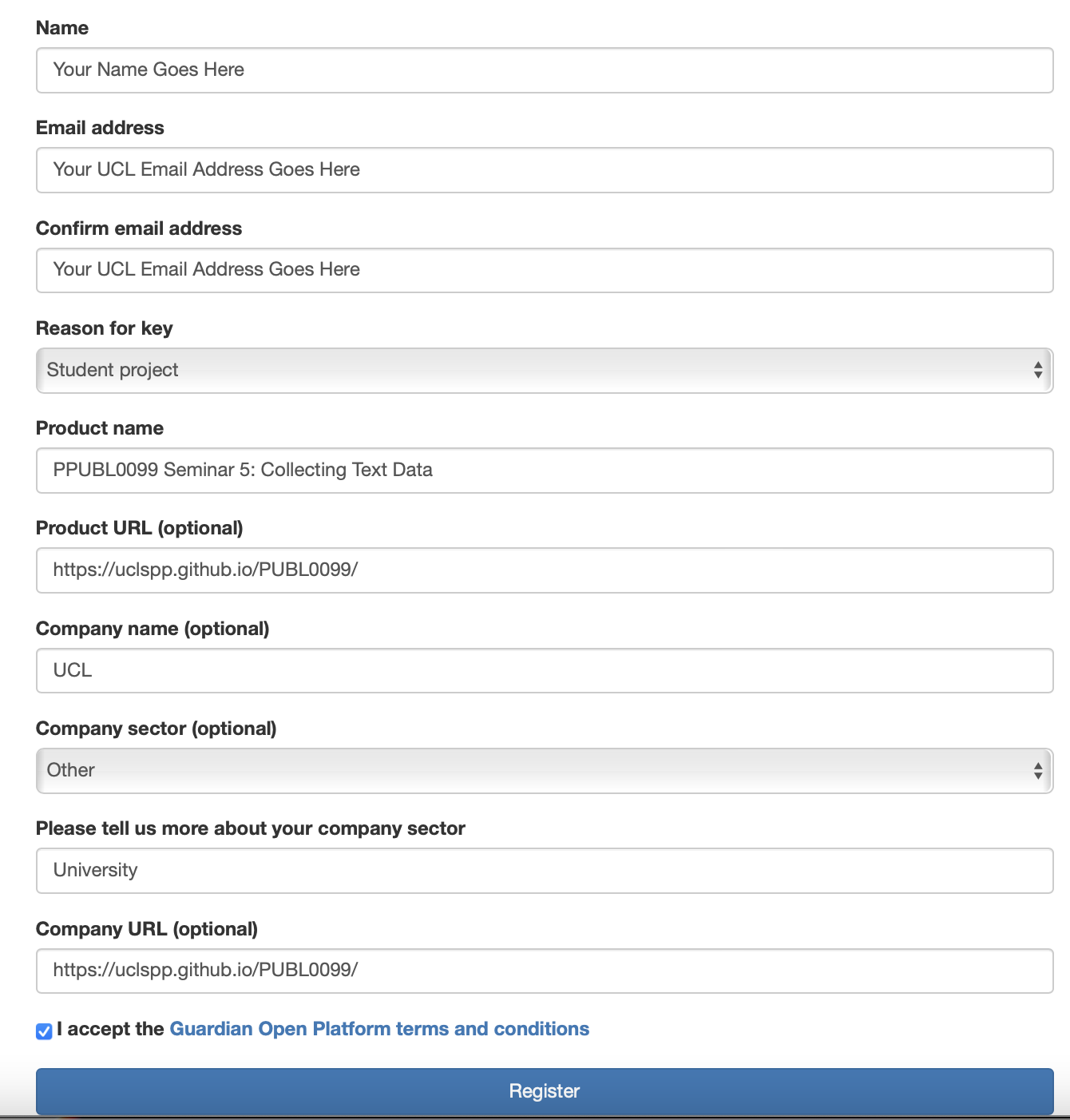
You should receive an email asking you to confirm your UCL email address, and then a second email which contains your API key. It will be a long string like "g257t1jk-df09-4a0c-8ae5-101010d94e428". Make sure you save this key somewhere!
You can then authenticate with the API by using the gu_api_key() function:
When you run that function, you will see the following message appear in your R console.
Please enter your API key and press enter:Paste the API key that you received via email into the console and you should see the following message:
Updating gu.API.key session variable...You should now be able to use the API functions that are available in the guardianapi package! We will cover some of these functions below.
5.3.2 Retrieve some newspaper articles
We will start by using the gu_content() function to retrieve some data from the API. This function takes a number of arguments, some of the more important ones are listed in the table below:
| Argument | Description |
|---|---|
query |
A string containing the search query. Today, you can choose a simple query which will retrieve any newspaper article published in the Guardian that contains that term. |
from_date |
The start date that we would like to constrain our search. This argument should be a character of the form "YYYY-MM-DD". We will use "2021-01-01" today so that we will gather articles published on the 1st January 2021 or later. |
to_date |
The end date of our search. We will use "2021-12-31", so as to collect articles up to 31st December 2021. |
production_office |
The Guardian operates in several countries and this argument allows us to specify which version of the Guardian we would like to collect data from. We will set this to "UK" so that we collect news stories published in the UK. |
Execute the
gu_content()function using the arguments as specified in the table above. There are two very important things to remember about this step:- Don’t forget to save the output of this function to an object!
- Don’t run this function more times than you need to (hopefully just once). Each time you run the function you are making repeated calls to the Guardian API and if you use it too many times you will exceed your rate limit for the day and will have to wait until tomorrow for it to reset.
Reveal code
I used the term
"china"for thequeryargument, but you can select whatever search term you like.
- Save the object you have created.
Reveal code
You can then load the data file (if you need to) using the load() function as usual:
- Inspect the output.
Reveal code
Rows: 4,738
Columns: 47
$ id <chr> "world/2022/nov/21/china-accused-of-s…
$ type <chr> "article", "article", "article", "art…
$ section_id <chr> "world", "world", "australia-news", "…
$ section_name <chr> "World news", "World news", "Australi…
$ web_publication_date <dttm> 2022-11-21 03:44:20, 2022-12-27 05:0…
$ web_title <chr> "China accused of seizing rocket debr…
$ web_url <chr> "https://www.theguardian.com/world/20…
$ api_url <chr> "https://content.guardianapis.com/wor…
$ tags <list> [<data.frame[9 x 15]>], [<data.frame…
$ is_hosted <lgl> FALSE, FALSE, FALSE, FALSE, FALSE, FA…
$ pillar_id <chr> "pillar/news", "pillar/news", "pillar…
$ pillar_name <chr> "News", "News", "News", "News", "News…
$ headline <chr> "China accused of seizing rocket debr…
$ standfirst <chr> "Coast guard cut towing cable the Phi…
$ trail_text <chr> "Coast guard cut towing cable the Phi…
$ byline <chr> "Rebecca Ratcliffe with agencies", "H…
$ main <chr> "<figure class=\"element element-imag…
$ body <chr> "<p> China’s coast guard forcibly sei…
$ wordcount <chr> "802", "1527", "583", "888", "726", "…
$ first_publication_date <dttm> 2022-11-21 03:44:20, 2022-12-27 05:0…
$ is_inappropriate_for_sponsorship <chr> "false", "false", "false", "false", "…
$ is_premoderated <chr> "false", "false", "false", "false", "…
$ last_modified <chr> "2024-11-08T19:23:50Z", "2023-01-05T0…
$ production_office <chr> "AUS", "AUS", "AUS", "UK", "UK", "AUS…
$ publication <chr> "theguardian.com", "The Guardian", "t…
$ short_url <chr> "https://www.theguardian.com/p/mm57h"…
$ should_hide_adverts <chr> "false", "false", "false", "false", "…
$ show_in_related_content <chr> "true", "true", "true", "true", "true…
$ thumbnail <chr> "https://media.guim.co.uk/3d44901c388…
$ legally_sensitive <chr> "false", "false", "false", "false", "…
$ lang <chr> "en", "en", "en", "en", "en", "en", "…
$ is_live <chr> "true", "true", "true", "true", "true…
$ body_text <chr> "China’s coast guard forcibly seized …
$ char_count <chr> "5123", "9441", "3478", "5585", "4408…
$ should_hide_reader_revenue <chr> "false", "false", "false", "false", "…
$ show_affiliate_links <chr> "false", "false", "false", "false", "…
$ byline_html <chr> "<a href=\"profile/rebecca-ratcliffe\…
$ show_table_of_contents <chr> "false", "false", "false", "false", "…
$ newspaper_page_number <chr> NA, "22", NA, "21", "42", NA, NA, "16…
$ newspaper_edition_date <date> NA, 2022-12-27, NA, 2022-12-22, 2022…
$ live_blogging_now <chr> NA, NA, NA, NA, NA, "false", NA, NA, …
$ comment_close_date <dttm> NA, NA, NA, NA, NA, NA, NA, NA, NA, …
$ commentable <chr> NA, NA, NA, NA, NA, NA, NA, NA, NA, N…
$ sensitive <chr> NA, NA, NA, NA, NA, NA, NA, NA, NA, N…
$ display_hint <chr> NA, NA, NA, NA, NA, NA, NA, NA, NA, N…
$ star_rating <chr> NA, NA, NA, NA, NA, NA, NA, NA, NA, N…
$ contributor_bio <chr> NA, NA, NA, NA, NA, NA, NA, NA, NA, N…We have successfully retrieved 4738 articles that contain the term
"china"in 2021.
We get a lot of information about these articles! In addition to the text of the article (
body_text), we also get the title of each article (web_title), the date of publication (first_publication_date), the section of the newspaper in which the article appeared (section_name), the author of the article (byline), as well as many other pieces of potentially useful metadata.
5.3.3 Analyse the Guardian Texts
- Convert the texts of these articles (use the
body_textvariable) into a quantedadfmobject. How many features are in yourdfm?
Reveal code
# Convert to corpus
gu_corpus <- corpus(gu_out, text_field = "body_text")
# Tokenize
gu_tokens <- gu_corpus %>%
tokens(remove_punct = T,
remove_symbols = T,
remove_url = T)
# Convert to DFM
gu_dfm <- gu_tokens %>%
dfm() %>%
dfm_remove(stopwords("en")) %>%
dfm_trim(max_docfreq = .9,
docfreq_type = "prop",
min_termfreq = 10)
gu_dfm- What are the most common words in this corpus of articles?
- Using the methods we covered in the first four weeks of the course, find out something interesting about the data you have collected. Produce at least one plot and write a paragraph of text explaining what you have discovered.
library(quanteda.dictionaries)
covid_dictionary <- c("covid*", "covid19", "covid-19", "coronavirus*", "lockdown*", "vaccination*")
covid_dictionary <- dictionary(list(covid = covid_dictionary))
gu_covid_dfm <- dfm_lookup(gu_dfm, covid_dictionary)
gu_covid_dfm_proportions <- gu_covid_dfm/ntoken(gu_dfm)
gu_out$covid <- as.numeric(gu_covid_dfm_proportions[,1])
gu_out %>%
ggplot(aes(x = web_publication_date,
y = covid)) +
geom_point() +
theme_bw() +
ylab("Proportion of COVID-19 words") +
xlab("Publication Date")5.3.4 Homework
Write a paragraph which describes a potential research project for this course. The paragraph should include the research question you intend to answer, the data that you would require to answer that question, and the method that you would apply for that purpose. You should indicate if you have already located the data needed, and how you intend to collect it for use in your project (can you just download it? Do you need to use an API? Do you need to do some web-scraping?). Upload your paragraph to this Moodle page.
5.4 Web-Scraping
Warning: Collecting data from the web (“web scraping”) is usually really annoying. There is no single function that will give you the information you need from a webpage. Instead, you must carefully and painfully write code that will give you what you want. If that sounds OK, then continue on with this problem set. If it doesn’t, stop here, and do something else.
5.4.1 Packages
You will need to load the following libraries to complete this part of the assignment (you may need to use install.packages() first):
rvestis a nice package which helps you to scrape information from web pages.xml2is a package which includes functions that can make it (somewhat) easier to navigate through html data that is loaded into R.
5.4.2 Overview
Throughout this course, the modal structure of a problem set has been that I give you a nice, clean, rectangular data.frame or tibble, which you use for the application of some fancy method. Here, I am going to walk through an example of getting the horrible, messy, and oddly-shaped data from a webpage, and turning it into a data.frame or tibble that is usable.
Since no two websites are the same, web scraping requires you to identify the relevant parts of the html code that lies behind websites. The goal here is to parse the HTML into usable data. Generally speaking, there are three main steps for webscraping:
- Access a web page from R
- Tell R where to “look” on the page
- Manipulate the data in a usable format within R.
- (We don’t speak about step 4 so much, but it normally includes smacking your head against your desk, wondering where things went wrong and generally questioning all your life choices. But we won’t dwell on that here.)
We are going to set ourselves a typical data science-type task in which we are going to scrape some data about politicians from their wiki pages. In particular, our task is to establish which universities were most popular amongst the crop of UK MPs who served in the House of Commons between 2017 and 2019. It is often useful to define in advance what the exact goal of the data collection task is. For us, we would like to finish with a data.frame or tibble that consists of one observations for each MP, and two variables: the MP’s name, and where they went to university.
5.4.3 Step 1: Scrape a list of current MPs
First, we need to know which MPs were in parliament in this period. A bit of googling shows that this wiki page gives us what we need. Scroll down a little, and you will see that there is a table where each row is an MP. It looks like this:
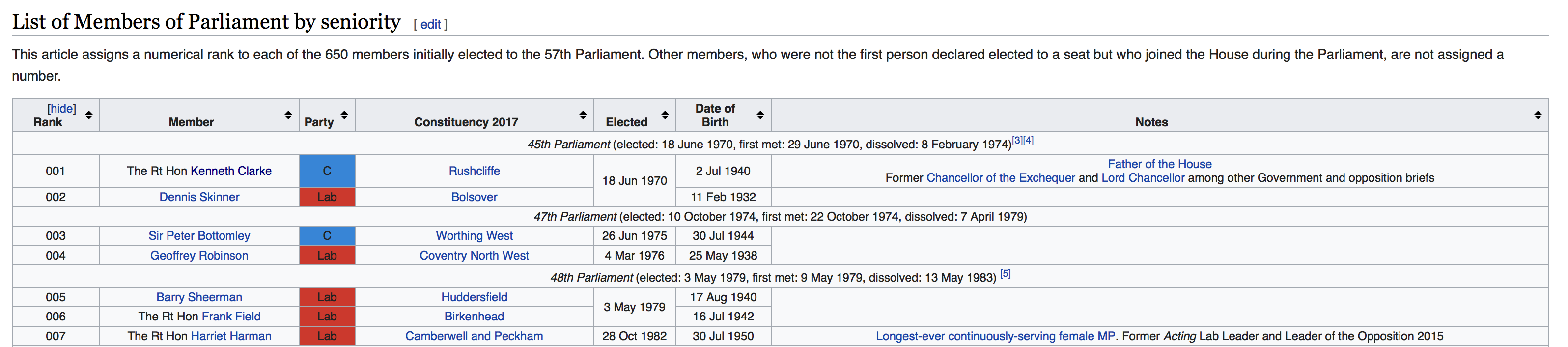
The nice thing about this is that an html table like this should be reasonably easy to work with. We will need to be able to work with the underlying html code of the wiki page in what follows, so you will need to be able to see the source code of the website. If you don’t know how to look at the source code, follow the relevant instructions on this page for the browser that you are using.
When you have figured that out, you should be able to see something that looks a bit like this: 
As you can see, html is horrible to look at. In R, we can read in the html code by using the read_html function from the rvest package:
read_html returns an XML document (to check, try running class(mps_list_page)), which makes navigating the different parts of the website (somewhat) easier.
Now that we have the html code in R, we need to find the parts of the webpage that contain the table. Scroll through the source code that you should have open in your browser to see if you can find the parts of the code that contain the table we are interested in.
On line 863, you should see something like <table class="wikitable collapsible sortable" style="text-align: center; font-size: 85%; line-height: 14px;">. This marks the beginning of the table that we are interested in, and we can ask rvest to extract that table from our mps_list_page object by using the html_elements function.
Here, the string we pass to the css argument tells rvest that we would like to grab the table from the object mps_list_page that has the class wikitable collapsible sortable. The object we have created (mp_table) is itself an XML object, which is good, because we will need to navigate through that table to get the information we need.
Now, within that table, we would like to extract two pieces of information for each MP: their name, and the link to their own individual wikipedia page. Looking back at the html source code, you should be able to see that each MP’s entry in the table is contained within its own separate <span> tag, and the information we are after is further nested within a <a> tag. For example, line 917 includes the following:

Yes, Bottomley is a funny name.
We would like to extract all of these entries from the table, and we can do so by again using html_elements and using the appropriate css expression, which here is "span a", because the information we want is included in the a tag which itself is nested within the span tag.
{xml_nodeset (655)}
[1] <a href="/wiki/Kenneth_Clarke" title="Kenneth Clarke">Kenneth Clarke</a>
[2] <a href="/wiki/Dennis_Skinner" title="Dennis Skinner">Dennis Skinner</a>
[3] <a href="/wiki/Sir_Peter_Bottomley" class="mw-redirect" title="Sir Peter ...
[4] <a href="/wiki/Geoffrey_Robinson_(politician)" title="Geoffrey Robinson ...
[5] <a href="/wiki/Barry_Sheerman" title="Barry Sheerman">Barry Sheerman</a>
[6] <a href="/wiki/Frank_Field_(British_politician)" class="mw-redirect" tit ...
[7] <a href="/wiki/Harriet_Harman" title="Harriet Harman">Harriet Harman</a>
[8] <a href="/wiki/Sir_Kevin_Barron" class="mw-redirect" title="Sir Kevin Ba ...
[9] <a href="/wiki/Sir_Edward_Leigh" class="mw-redirect" title="Sir Edward L ...
[10] <a href="/wiki/Nick_Brown" title="Nick Brown">Nick Brown</a>
[11] <a href="/wiki/Jeremy_Corbyn" title="Jeremy Corbyn">Jeremy Corbyn</a>
[12] <a href="/wiki/Sir_David_Amess" class="mw-redirect" title="Sir David Ame ...
[13] <a href="/wiki/Sir_Roger_Gale" class="mw-redirect" title="Sir Roger Gale ...
[14] <a href="/wiki/Sir_Nicholas_Soames" class="mw-redirect" title="Sir Nicho ...
[15] <a href="/wiki/Dame_Margaret_Beckett" class="mw-redirect" title="Dame Ma ...
[16] <a href="/wiki/Sir_Bill_Cash" class="mw-redirect" title="Sir Bill Cash"> ...
[17] <a href="/wiki/Ann_Clwyd" title="Ann Clwyd">Ann Clwyd</a>
[18] <a href="/wiki/Sir_Patrick_McLoughlin" class="mw-redirect" title="Sir Pa ...
[19] <a href="/wiki/Sir_George_Howarth" class="mw-redirect" title="Sir George ...
[20] <a href="/wiki/Sir_John_Redwood" class="mw-redirect" title="Sir John Red ...
...Finally, now that we have the entry for each MP, it is very simple to extract the name of the MP and the URL to their wikipedia page:
# html_text returns the text between the tags (here, the MPs' names)
mp_names <- html_text(mp_table_entries)
# html_attr returns the attrubutes of the tags that you have named. Here we have asked for the "href" which will give us the link to each MP's own wiki page
mp_hrefs <- html_attr(mp_table_entries,
name = "href")
# Combine into a tibble
mps <- tibble(name = mp_names, url = mp_hrefs, university = NA, stringsAsFactors = FALSE)
head(mps)# A tibble: 6 × 4
name url university stringsAsFactors
<chr> <chr> <lgl> <lgl>
1 Kenneth Clarke /wiki/Kenneth_Clarke NA FALSE
2 Dennis Skinner /wiki/Dennis_Skinner NA FALSE
3 Sir Peter Bottomley /wiki/Sir_Peter_Bottomley NA FALSE
4 Geoffrey Robinson /wiki/Geoffrey_Robinson_(poli… NA FALSE
5 Barry Sheerman /wiki/Barry_Sheerman NA FALSE
6 Frank Field /wiki/Frank_Field_(British_po… NA FALSE OK, OK, so those urls are not quite complete. We need to fix “https://en.wikipedia.org” to the front of them first. We can do that using the paste0() function:
# A tibble: 6 × 4
name url university stringsAsFactors
<chr> <chr> <lgl> <lgl>
1 Kenneth Clarke https://en.wikipedia.org/wiki… NA FALSE
2 Dennis Skinner https://en.wikipedia.org/wiki… NA FALSE
3 Sir Peter Bottomley https://en.wikipedia.org/wiki… NA FALSE
4 Geoffrey Robinson https://en.wikipedia.org/wiki… NA FALSE
5 Barry Sheerman https://en.wikipedia.org/wiki… NA FALSE
6 Frank Field https://en.wikipedia.org/wiki… NA FALSE That’s better. Though, wait, how many observations are there in our data.frame?
655? But there are only 650 MPs in the House of Commons! Oh, I know why, it’s because some MPs will have left/died/been caught in a scandal and therefore have been replaced…
Are you still here? Well done! We have something! We have…a list of MPs’ names! But we don’t have anything else. In particular, we still do not know where these people went to university. To find that, we have to move on to step 2.
5.4.4 Step 2: Scrape the wiki page for each MP
Let’s look at the page for the first MP in our list: https://en.wikipedia.org/wiki/Kenneth_Clarke. Scroll down the page, looking at the panel on the right-hand side. At the bottom of the panel, you will see this:

The bottom line gives Clarke’s alma mater, which in this case is one of the Cambridge colleges. That is the information we are after. If we look at the html source code for this page, we can see that the alma mater line of the panel is enclosed in another <a> tag:

Now that we know this, we can call in the html using read_html again:
And then we can use html_elements and html_text to extract the name of the university. Here we use a somewhat more complicated argument to find the information we are looking for. The xpath argument tells rvest to look for the tag a with a title of "Alma mater", and then asking rvest to look for the next a tag that comes after the alma mater tag. This is because the name of the university is actually stored in the subsequent a tag.
mp_university <- html_elements(mp_text,
xpath = "//a[@title='Alma mater']/following::a[1]") %>%
html_text()
print(mp_university)[1] "Gonville and Caius College, Cambridge"Regardless of whether you followed that last bit: it works! We now know where Kenneth Clarke went to university. Finally, we can assign the university that he went to to the mps tibble that we created earlier:
# A tibble: 6 × 4
name url university stringsAsFactors
<chr> <chr> <chr> <lgl>
1 Kenneth Clarke https://en.wikipedia.org/wiki… Gonville … FALSE
2 Dennis Skinner https://en.wikipedia.org/wiki… <NA> FALSE
3 Sir Peter Bottomley https://en.wikipedia.org/wiki… <NA> FALSE
4 Geoffrey Robinson https://en.wikipedia.org/wiki… <NA> FALSE
5 Barry Sheerman https://en.wikipedia.org/wiki… <NA> FALSE
6 Frank Field https://en.wikipedia.org/wiki… <NA> FALSE 5.4.5 Scraping exercises (Homework)
- Figure out how to collect this university information for all of the other MPs in the data. You will need to write a for-loop, which iterates over the URLs in the
data.framewe just constructed and pulls out the relevant information from each MP’s wiki page. You will find very quickly that web-scraping is a messy business, and your loop will probably fail. You might want to use thestop,next,tryandiffunctions to help avoid problems.
- Which was the modal university for the current set of UK MPs?
- Go back to the scraping code and see if you can add some more variables to the
tibble. Can you scrape the MPs’ party affiliations? Can you scrape their date of birth? Doing so will require you to look carefully at the html source code, and work out the appropriate xpath expression to use. For guidance on xpath, see here.
- If you got this far, well done! In your homework upload you should tell me how many Labour and Conservative MPs went to UCL and I will shower you with praise.