7 Vector Space Models & Text Classification
7.1 Seminar
7.1.1 Exercise
This exercise is designed to get you working with quanteda. The focus will be on exploring the package and getting some texts into the corpus object format. quanteda package has several functions for creating a corpus of texts which we will use in this exercise.
Getting Started.
You will first need to install some packages:
install.packages(c("tm", "readtext", "quanteda"))You will also need to install the package
quantedaDatafrom github using theinstall_githubfunction from thedevtoolspackage:devtools::install_github('kbenoit/quantedaData')Exploring quanteda functions.
library(tm) library(quanteda) library(quantedaData) library(readtext)Look at the Quick Start vignette, and browse the manual for quanteda. You can use
example()function for any function in the package, to run the examples and see how the function works. Of course you should also browse the documentation, especially?corpusto see the structure and operations of how to construct a corpus. The website http://quanteda.io has extensive documentation.?corpus example(dfm) example(corpus)Making a corpus and corpus structure
From a vector of texts already in memory.
The simplest way to create a corpus is to use a vector of texts already present in R’s global environment. Some text and corpus objects are built into the package, for example
data_char_ukimmig2010is the UTF-8 encoded set of 9 UK party manifesto sections from 2010, that deal with immigration policy. addresses. Try usingcorpus()on this set of texts to create a corpus.Once you have constructed this corpus, use the
summary()method to see a brief description of the corpus. The names of the corpusdata_char_ukimmig2010should have become the document names.immig_corpus <- corpus(data_char_ukimmig2010) summary(immig_corpus)Corpus consisting of 9 documents: Text Types Tokens Sentences BNP 1125 3280 88 Coalition 142 260 4 Conservative 251 499 15 Greens 322 679 21 Labour 298 683 29 LibDem 251 483 14 PC 77 114 5 SNP 88 134 4 UKIP 346 723 27 Source: /home/travis/build/UCLSPP/PUBLG088/_book/data/* on x86_64 by travis Created: Wed Dec 20 23:40:53 2017 Notes:From a directory of text files.
The
readtext()function from the readtext package can read (almost) any set of files into an object that you can then call thecorpus()function on, to create a corpus. (See?readtextfor an example.)Here you are encouraged to select any directory of plain text files of your own.
How did it work? Try usingdocvars()to assign a set of document-level variables. If you do not have a set of text files to work with, then you can use the UK 2010 manifesto texts on immigration, in the Day 8 folder, like this:require(quanteda) manfiles <- readtext("https://github.com/kbenoit/ME114/raw/master/day8/UKimmigTexts.zip") mycorpus <- corpus(manfiles)From
.csvor.jsonfiles — see the documentation for the packagereadtext(help(package = "readtext")).Here you can try one of your own examples, or just file this in your mental catalogue for future reference.
Explore some phrases in the text.
You can do this using the
kwic(for “key-words-in-context”) to explore a specific word or phrase.kwic(data_corpus_inaugural, "terror", 3)[1797-Adams, 1325] violence, by | terror | [1933-Roosevelt, 112] unreasoning, unjustified | terror | [1941-Roosevelt, 287] by a fatalistic | terror | [1961-Kennedy, 866] uncertain balance of | terror | [1981-Reagan, 813] Americans from the | terror | [1997-Clinton, 1055] the fanaticism of | terror | [1997-Clinton, 1655] strong defense against | terror | [2009-Obama, 1632] aims by inducing | terror | , intrigue, which paralyzes needed , we proved that stays the of runaway living . And they and destruction. and slaughtering innocentsTry substituting your own search terms, or working with your own corpus.
head(kwic(data_corpus_inaugural, "america", 3))[1793-Washington, 63] people of united | America | [1797-Adams, 16] middle course for | America | [1797-Adams, 427] the people of | America | [1797-Adams, 1419] the people of | America | [1797-Adams, 2004] aboriginal nations of | America | [1797-Adams, 2152] the people of | America | . Previous to remained between unlimited were not abandoned have exhibited to , and a and the internalhead(kwic(data_corpus_inaugural, "democracy", 3))[1825-Adams, 1546] a confederated representative | democracy | [1841-Harrison, 525] to that of | democracy | [1841-Harrison, 1585] a simple representative | democracy | [1841-Harrison, 7463] the name of | democracy | [1841-Harrison, 7894] of devotion to | democracy | [1921-Harding, 1087] temple of representative | democracy | were a government . If such or republic, they speak, . The foregoing , to beCreate a document-feature matrix, using
dfm. First, read the documentation using?dfmto see the available options.mydfm <- dfm(data_corpus_inaugural, remove = stopwords("english")) mydfmDocument-feature matrix of: 58 documents, 9,221 features (92.6% sparse).topfeatures(mydfm, 20), . - people ; government 7026 4945 762 575 565 564 us can upon must great may 478 471 371 366 340 338 states shall world country every nation 333 314 311 304 298 293 peace one 254 252Experiment with different
dfmoptions, such asstem = TRUE. The functiondfm_trim()allows you to reduce the size of the dfm following its construction.dim(dfm(data_corpus_inaugural, stem = TRUE))[1] 58 5541dim(dfm_trim(mydfm, min_count = 5, min_docfreq = 0.01))[1] 58 2596Grouping on a variable is an excellent feature of
dfm(), in fact one of my favorites.
For instance, if you want to aggregate all speeches by presidential name, you can executemydfm <- dfm(data_corpus_inaugural, groups = "President") mydfmDocument-feature matrix of: 35 documents, 9,357 features (88.3% sparse).docnames(mydfm)[1] "Washington" "Adams" "Jefferson" "Madison" "Monroe" [6] "Jackson" "Van Buren" "Harrison" "Polk" "Taylor" [11] "Pierce" "Buchanan" "Lincoln" "Grant" "Hayes" [16] "Garfield" "Cleveland" "McKinley" "Roosevelt" "Taft" [21] "Wilson" "Harding" "Coolidge" "Hoover" "Truman" [26] "Eisenhower" "Kennedy" "Johnson" "Nixon" "Carter" [31] "Reagan" "Bush" "Clinton" "Obama" "Trump"Note that this groups Theodore and Franklin D. Roosevelt together – to separate them we would have needed to add a firstname variable using
docvars()and grouped on that as well.Do this to aggregate the Irish budget corpus (
data_corpus_irishbudget2010) by political party, when creating a dfm.mydfm <- dfm(data_corpus_inaugural, remove = stopwords("english"), remove_punct = TRUE, stem = TRUE) topfeatures(mydfm, 20)nation govern peopl us can state great 675 657 623 478 471 450 373 upon power must countri world may shall 371 370 366 355 339 338 314 everi constitut peac right law time 298 286 283 276 271 267irish_dfm <- dfm(data_corpus_irishbudget2010, groups = "party")summary(irish_dfm)Explore the ability to subset a corpus.
There is a
corpus_subset()method defined for a corpus, which works just like R’s normalsubset()command. For instance if you want a wordcloud of just Obama’s two inagural addresses, you would need to subset the corpus first:obamadfm <- dfm(corpus_subset(data_corpus_inaugural, President=="Obama")) textplot_wordcloud(obamadfm)
Try producing that plot without the stopwords. See
dfm_remove()to remove stopwords from the dfm object directly, or supply theremoveargument todfm().obamadfm <- dfm(corpus_subset(data_corpus_inaugural, President=="Obama"), remove = stopwords("SMART"), remove_punct = TRUE)Warning: 'stopwords(language = "SMART")' is deprecated. Use 'stopwords(source = "smart")' instead. See help("Deprecated")textplot_wordcloud(obamadfm)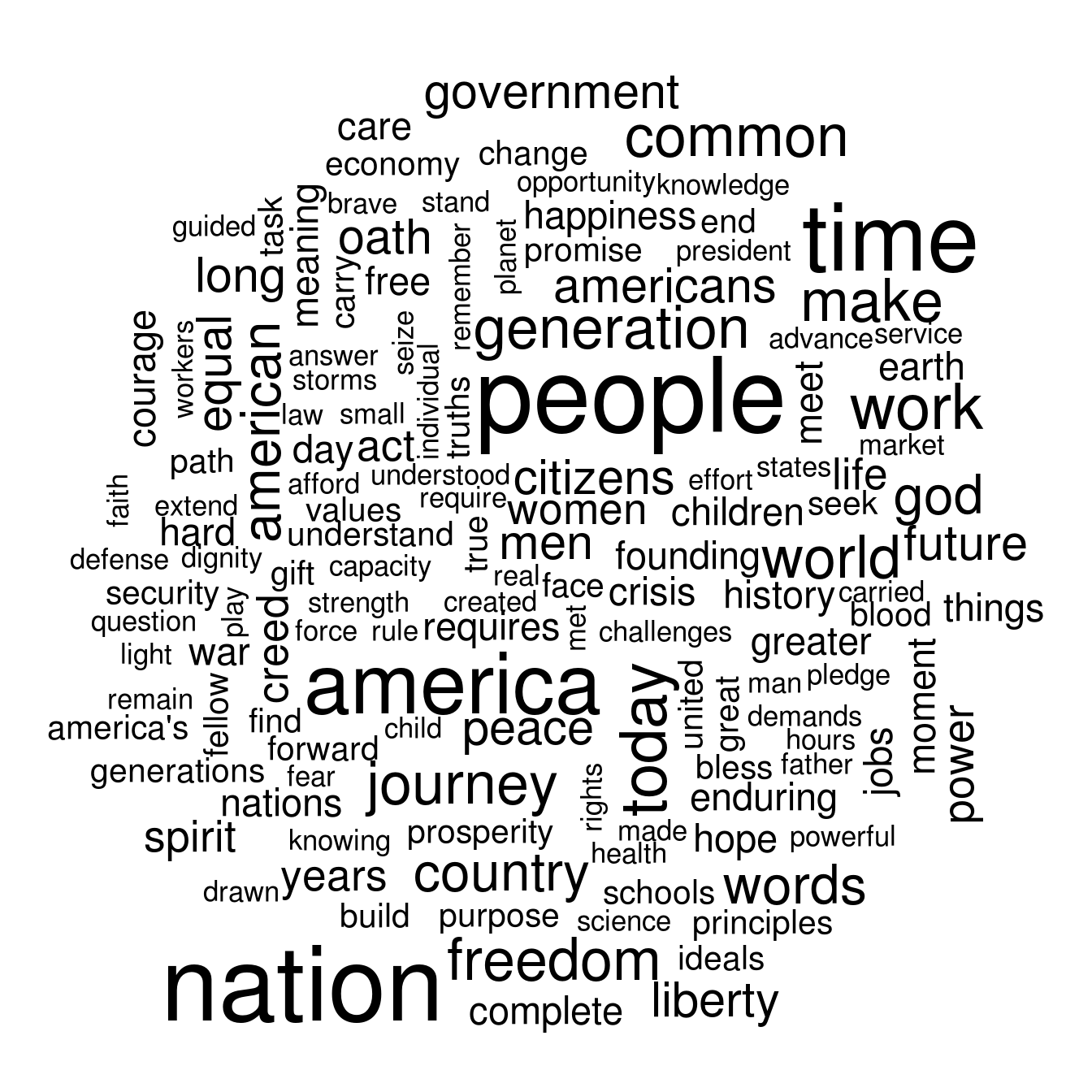
Preparing and pre-processing texts
“Cleaning”" texts
It is common to “clean” texts before processing, usually by removing punctuation, digits, and converting to lower case. Look at the documentation for
char_tolower()and use the command on thedata_char_sampletexttext (you can load this from quantedaData usingdata(data_char_sampletext). Can you think of cases where cleaning could introduce homonymy?sample_text_lowercase <- char_tolower(data_char_sampletext)Tokenizing texts
In order to count word frequencies, we first need to split the text into words through a process known as tokenization. Look at the documentation for quanteda’s
tokens()function. Use thetokenscommand ondata_char_sampletext, and examine the results. Are there cases where it is unclear where the boundary between two words lies? You can experiment with the options totokens.Try tokenizing the sentences from
data_char_sampletextinto sentences, usingtokens(x, what = "sentence").tokens(sample_text_lowercase) tokens(sample_text_lowercase, remove_hyphens = TRUE) tokens(sample_text_lowercase, remove_numbers = TRUE, remove_punct = TRUE, remove_symbols = TRUE)tokens(sample_text_lowercase, what = "sentence")tokens from 1 document. text1 : [1] "instead we have a fine gael-labour party government, coming into power promising real change but slavishly following the previous government's policy. that policy has been dictated by the imf, the eu and the ecb not to bail out the irish people but to salvage german, french, british banks and those of other countries from their disastrous and frenzied embrace of irish bankers and speculators in the irish property market bubble. it is criminal that an irish government would ever slavishly agree to make a vassal state of the republic of ireland and its people, to squeeze tribute from our people to save the capitalist banks of europe and in doing so destroy the lives of hundreds of thousands of our people now plunged into unemployment, financial hardship and social dislocation. in this budget and the past four years the austerity policy means €25 billion has been reefed out of the irish economy in pursuit of a policy of cringing acceptance of the diktats of the financial markets. can this government not see that, not only is this immoral and unjust in the extreme, it is decimating the domestic economy?" [2] "as we are tired of pointing out, if we savage the ability of the majority of our people to purchase goods and utilise services, then tens of thousands of workers depending on this demand for their jobs will be thrown on the scrapheap of unemployment and, tragically, that is what is happening. all the key indicators in the domestic economy show the abject failure of austerity. private investment has collapsed, vat receipts are more than €400 million behind and unemployment has risen by thousands since this government entered office. much is made of the growth in exports. every job in the export sector is vital and we defend it but the type of investment and the capital intensive nature of the investment that goes into exports means that it is not where the hundreds of thousands of jobs we need will be created in the next period of years. on the other hand, taking €670 million from the pockets of ordinary people through the vat increases and taking other money in the cuts in child benefit and elsewhere will further add to the downward spiral of austerity. the interest relief for householders who are trapped in the nightmare of negative equity and extortionate monthly mortgage payments will be welcomed to a degree but is dismally inadequate. that generation of workers who are trapped in this nightmare are victims of the extortion perpetrated on them in the housing market by the immoral speculators legislated for by fianna fáil and the pds. the huge proportion of their incomes that continues to go to the banks massively dislocates the economy. otherwise those funds would be going to the purchase of goods and services in the domestic economy, stimulating demand and sustaining tens of thousands of jobs for tens of thousands of people who are now on the dole, unfortunately."Stemming.
Stemming removes the suffixes using the Porter stemmer, found in the SnowballC library. The quanteda function* to invoke the stemmer end with
*_wordstem. Apply stemming to thedata_char_sampletext(usingchar_wordstem()) and examine the results. Why does it not appear to work, and what do you need to do to make it work? How would you apply this to the sentence-segmented vector?# Word-segmented vector sample_word_stems <- char_wordstem(tokens(data_char_sampletext)[[1]]) sample_word_stems[1:10][1] "Instead" "we" "have" "a" "Fine" [6] "Gael-Labour" "Parti" "Govern" "," "come"# Sentence-segmented vector sentence_boundaries <- c(0, which(sample_word_stems == ".")) sample_sentence_word_stems <- list() for(i in 1:(length(sentence_boundaries)-1)) { sample_sentence_word_stems[[i]] <- paste0(sample_word_stems[(sentence_boundaries[i] + 1):(sentence_boundaries[i+1])], collapse = " ") } sample_sentence_word_stems[1:3][[1]] [1] "Instead we have a Fine Gael-Labour Parti Govern , come into power promis real chang but slavish follow the previous Govern polici ." [[2]] [1] "That polici has been dictat by the IMF , the EU and the ECB not to bail out the Irish peopl but to salvag German , French , British bank and those of other countri from their disastr and frenzi embrac of Irish banker and specul in the Irish properti market bubbl ." [[3]] [1] "It is crimin that an Irish Govern would ever slavish agre to make a vassal State of the Republ of Ireland and it peopl , to squeez tribut from our peopl to save the capitalist bank of Europ and in do so destroy the live of hundr of thousand of our peopl now plung into unemploy , financi hardship and social disloc ."Applying “pre-processing” to the creation of a
dfm.quanteda’s
dfm()function makes it wasy to pass the cleaning arguments to clean, which are executed as part of the tokenization implemented bydfm(). Compare the steps required in a similar text preparation package, tm:require(tm) data("crude") crude <- tm_map(crude, content_transformer(tolower)) crude <- tm_map(crude, removePunctuation) crude <- tm_map(crude, removeNumbers) crude <- tm_map(crude, stemDocument) tdm <- TermDocumentMatrix(crude) # same in quanteda require(quanteda) crudeCorpus <- corpus(crude) crudeDfm <- dfm(crudeCorpus)Inspect the dimensions of the resulting objects, including the names of the words extracted as features. It is also worth comparing the structure of the document-feature matrixes returned by each package. tm uses the slam simple triplet matrix format for representing a sparse matrix.
It is also – in fact almost always – useful to inspect the structure of this object:
str(tdm)List of 6 $ i : int [1:1877] 42 77 100 136 148 158 163 164 174 180 ... $ j : int [1:1877] 1 1 1 1 1 1 1 1 1 1 ... $ v : num [1:1877] 1 2 1 1 2 2 1 1 2 2 ... $ nrow : int 848 $ ncol : int 20 $ dimnames:List of 2 ..$ Terms: chr [1:848] "abdulaziz" "abil" "abl" "about" ... ..$ Docs : chr [1:20] "127" "144" "191" "194" ... - attr(*, "class")= chr [1:2] "TermDocumentMatrix" "simple_triplet_matrix" - attr(*, "weighting")= chr [1:2] "term frequency" "tf"THis indicates that we can extract the names of the words from the tm TermDocumentMatrix object by getting the rownames from inspecting the tdm:
head(tdm$dimnames$Terms, 20)[1] "abdulaziz" "abil" "abl" "about" "abov" [6] "abroad" "accept" "accord" "across" "activ" [11] "add" "address" "adher" "advantag" "advis" [16] "after" "again" "against" "agenc" "agre"Compare this to the results of the same operations from quanteda. To get the “words” from a quanteda object, you can use the
featnames()function:features_quanteda <- featnames(crudeDfm) head(features_quanteda, 20)[1] "diamond" "shamrock" "corp" "said" "that" "effect" [7] "today" "it" "had" "cut" "contract" "price" [13] "for" "crude" "oil" "by" "dlrs" "a" [19] "barrel" "the"str(crudeDfm)Formal class 'dfm' [package "quanteda"] with 15 slots ..@ settings :List of 1 .. ..$ : NULL ..@ weightTf :List of 3 .. ..$ scheme: chr "count" .. ..$ base : NULL .. ..$ K : NULL ..@ weightDf :List of 5 .. ..$ scheme : chr "unary" .. ..$ base : NULL .. ..$ c : NULL .. ..$ smoothing: NULL .. ..$ threshold: NULL ..@ smooth : num 0 ..@ ngrams : int 1 ..@ skip : int 0 ..@ concatenator: chr "_" ..@ version : int [1:3] 0 99 9031 ..@ docvars :'data.frame': 20 obs. of 15 variables: .. ..$ datetimestamp: chr [1:20] "1987-02-26 17:00:56" "1987-02-26 17:34:11" "1987-02-26 18:18:00" "1987-02-26 18:21:01" ... .. ..$ description : chr [1:20] "" "" "" "" ... .. ..$ heading : chr [1:20] "DIAMOND SHAMROCK (DIA) CUTS CRUDE PRICES" "OPEC MAY HAVE TO MEET TO FIRM PRICES - ANALYSTS" "TEXACO CANADA <TXC> LOWERS CRUDE POSTINGS" "MARATHON PETROLEUM REDUCES CRUDE POSTINGS" ... .. ..$ id : chr [1:20] "127" "144" "191" "194" ... .. ..$ language : chr [1:20] "en" "en" "en" "en" ... .. ..$ origin : chr [1:20] "Reuters-21578 XML" "Reuters-21578 XML" "Reuters-21578 XML" "Reuters-21578 XML" ... .. ..$ topics : chr [1:20] "YES" "YES" "YES" "YES" ... .. ..$ lewissplit : chr [1:20] "TRAIN" "TRAIN" "TRAIN" "TRAIN" ... .. ..$ cgisplit : chr [1:20] "TRAINING-SET" "TRAINING-SET" "TRAINING-SET" "TRAINING-SET" ... .. ..$ oldid : chr [1:20] "5670" "5687" "5734" "5737" ... .. ..$ places : chr [1:20] "usa" "usa" "canada" "usa" ... .. ..$ author : chr [1:20] NA "BY TED D'AFFLISIO, Reuters" NA NA ... .. ..$ orgs : chr [1:20] NA "opec" NA NA ... .. ..$ people : chr [1:20] NA NA NA NA ... .. ..$ exchanges : chr [1:20] NA NA NA NA ... ..@ i : int [1:2086] 0 0 0 10 17 0 1 2 3 4 ... ..@ p : int [1:876] 0 1 2 5 25 36 41 48 65 69 ... ..@ Dim : int [1:2] 20 875 ..@ Dimnames :List of 2 .. ..$ docs : chr [1:20] "127" "144" "191" "194" ... .. ..$ features: chr [1:875] "diamond" "shamrock" "corp" "said" ... ..@ x : num [1:2086] 2 1 1 3 1 3 11 1 1 3 ... ..@ factors : list()What proportion of the
crudeDfmare zeros? Compare the sizes oftdmandcrudeDfmusing theobject.size()function.prop.table(table(as.matrix(crudeDfm)==0))FALSE TRUE 0.1192 0.8808print(object.size(crudeDfm), units= "Mb")0.1 Mbprint(object.size(tdm), units= "Mb")0.1 Mb
Keywords-in-context
quanteda provides a keyword-in-context function that is easily usable and configurable to explore texts in a descriptive way. Type
?kwicto view the documentation.For the Irish budget debate speeches corpus for the year 2010, called
data_corpus_irishbudget2010, experiment with thekwicfunction, following the syntax specified on the help page forkwic.kwiccan be used either on a character vector or a corpus object. What class of object is returned? Try assigning the return value fromkwicto a new object and then examine the object by clicking on it in the environment pane in RStudio (or using the inspection method of your choice).northern_kwic <- kwic(data_corpus_irishbudget2010, "Northern") class(northern_kwic) # Class = data.frame or kwic object[1] "kwic" "data.frame"Use the
kwicfunction to discover the context of the word “clean”. Is this associated with environmental policy?clean_kwic <- kwic(data_corpus_irishbudget2010, "clean") # No, more like corruption! print(clean_kwic)[2010_BUDGET_03_Joan_Burton_LAB, 5266] pay the cost of the | [2010_BUDGET_06_Enda_Kenny_FG, 169] recovery, a strategy to | [2010_BUDGET_06_Enda_Kenny_FG, 1240] , while the people who | [2010_BUDGET_08_Eamon_Gilmore_LAB, 3551] strengths in sectors such as | clean | up and restore the gang clean | up the banks and a clean | out the Taoiseach's offices- clean | technology, food and theBy default, kwic explores all words related to the word, since it interprets the pattern as a “regular expression”. What if we wanted to see only the literal, entire word “disaster”? Hint: Look at the arguments using
?kwic.disaster_kwic <- kwic(data_corpus_irishbudget2010, "disaster", valuetype = "fixed")
Descriptive statistics
We can extract basic descriptive statistics from a corpus from its document feature matrix. Make a dfm from the 2010 Irish budget speeches corpus.
irish_dfm <- dfm(data_corpus_irishbudget2010, remove_punct = TRUE)Examine the most frequent word features using
textstat_frequency(). What are the five most frequent word in the corpus? (Note: There is a also atopfeatures()command that works in a similar way.)head(textstat_frequency(irish_dfm), 5)feature frequency rank docfreq 1 the 3598 1 14 2 to 1633 2 14 3 of 1537 3 14 4 and 1359 4 14 5 in 1231 5 14topfeatures(irish_dfm,5)the to of and in 3598 1633 1537 1359 1231quanteda provides a function to count syllables in a word —
nsyllable(). Try the function at the prompt. The code below will apply this function to all the words in the corpus, to give you a count of the total syllables in the corpus.# count syllables from texts in the 2010 speech corpus textsyls <- nsyllable(texts(data_corpus_irishbudget2010)) # sum the syllable counts sum(textsyls)[1] 80284How would you get the total syllables per text?
print(textsyls)[1] 13370 6313 9126 10569 10260 6172 3155 6081 1869 1842 1517 [12] 2293 1793 5924